What does Headroom actually do?
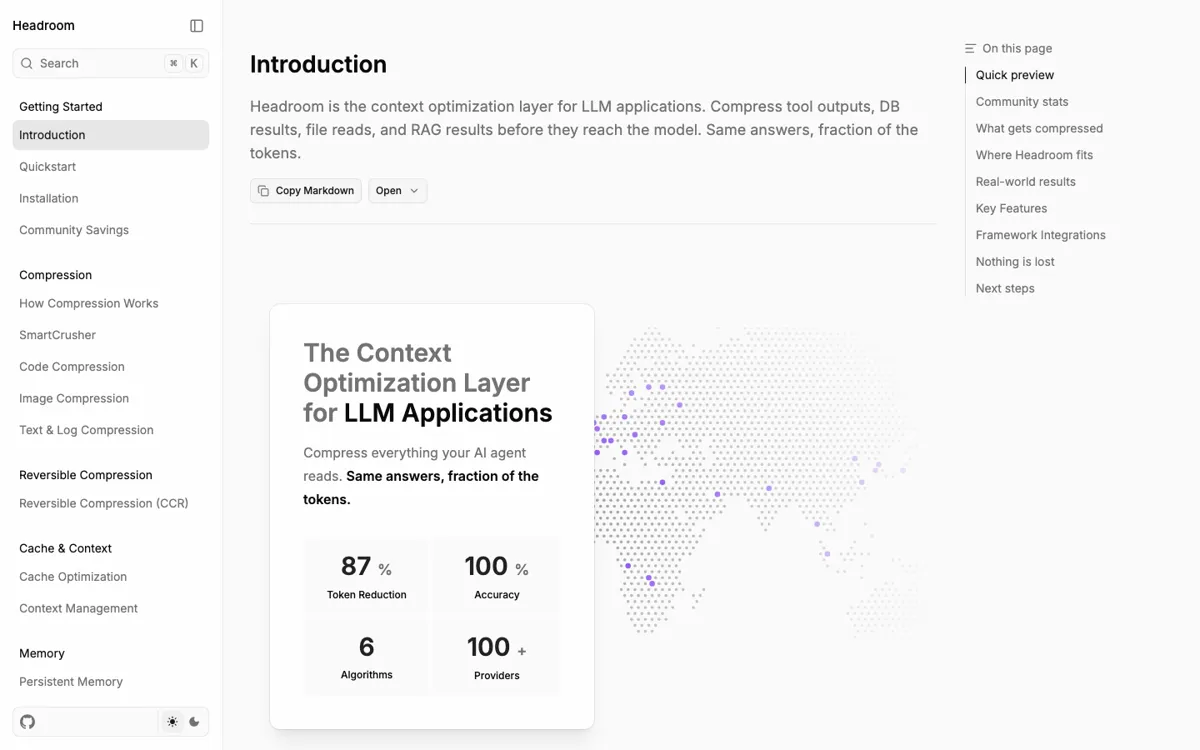
Headroom sits in the part of an AI stack where context waste usually accumulates: tool output, logs, RAG retrievals, API responses, database rows, and repeated file reads. Instead of asking the model to read everything raw, it compresses content before the provider call. The notable point is that it is not locked to one integration style. A developer can call a Python function, use a TypeScript SDK path through a local proxy, run a standalone HTTP proxy, wrap a coding agent from the CLI, or expose compression through MCP tools.
The technical bet is reversible compression. SmartCrusher handles structured JSON-like output, code paths can go through AST-aware compression, prose can use Kompress, and CCR stores originals so the agent can retrieve source detail if the compressed version is too thin. That matters for agent work because a bad summary can silently remove the one line that explained the failure. Headroom is trying to reduce tokens without turning compression into irreversible deletion.